
Designing Intelligent Document Processing – an Agentic RAG Architecture
How I built a graph-orchestrated, schema-guided Intelligent Document Processing system for enterprise-ready document intelligence. This POC intentionally balances simplicity with production-grade architectural thinking. It avoids over-engineering while still modeling scalable Generative AI system design.
The Real Challenge in Enterprise AI Systems
In the current wave of Generative AI, most applications focus on chatbots, summarization tools, or basic question-answering systems. While these use cases are valuable, they do not fully address one of the largest industrial challenge which can become the most relevant use case:
Intelligent Document Processing (IDP).
Invoices, contracts, bank statements, payslips, insurance claims, resumes — enterprises handle thousands of such documents daily. Traditional automation systems rely heavily on:
- OCR + regex pipelines
- Hardcoded document templates
- Rule-based validation engines
These deterministic systems struggle with real-world variability.
On the other hand, Large Language Models (LLMs) offer flexibility but introduce probabilistic uncertainty.
To explore, how to combine the flexibility of LLMs with the control and reliability required in enterprise systems, I built a Proof-of-Concept using an Agentic AI architecture with Retrieval-Augmented Generation (RAG) and a semantic schema layer.
Why Traditional RAG Architecture Is Not Enough
A standard RAG architecture typically looks like this:

This works well for:
- Knowledge base Q&A
- AI chatbots
- Semantic search systems
But document workflows require more:
- Structured field extraction
- Conditional routing
- Multi-step reasoning
- Confidence scoring
- Validation against expected formats
Plain RAG lacks deterministic orchestration which is very essential for Intelligent Document processing.
To solve this, I used LangGraph, part of the LangChain ecosystem, to introduce stateful control over execution flow.
High-Level Architecture Overview
The system is designed as a graph-orchestrated Agentic AI pipeline.Below is a simplified architectural flow:

Detailed Architectural Diagram
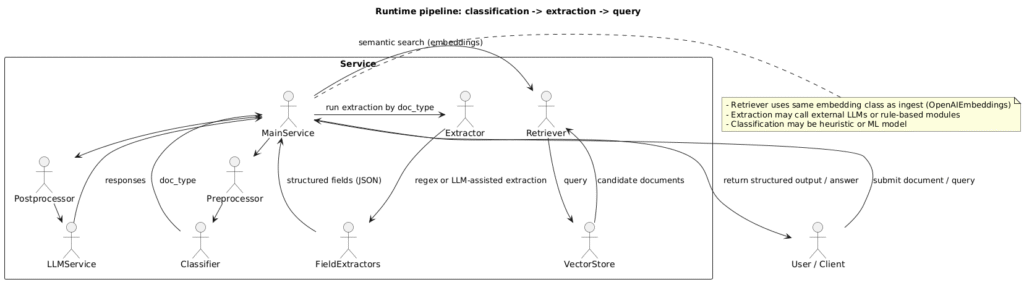
- Knowledge Layer (Vector DB)
- Orchestration Layer (LangGraph)
- Execution Layer (LLM)
- Validation Layer
- Confidence Layer
Why LangGraph Instead of Simple LangChain Chains?
Traditional LangChain chains are primarily linear.
For simple pipelines, that works well:
Input → LLM → Output
But intelligent document processing workflows are rarely linear.
They require:
- Classification before extraction
- Conditional routing based on document type
- Validation logic
- Retrieval from memory
- Structured output enforcement
- Retry handling
This becomes:
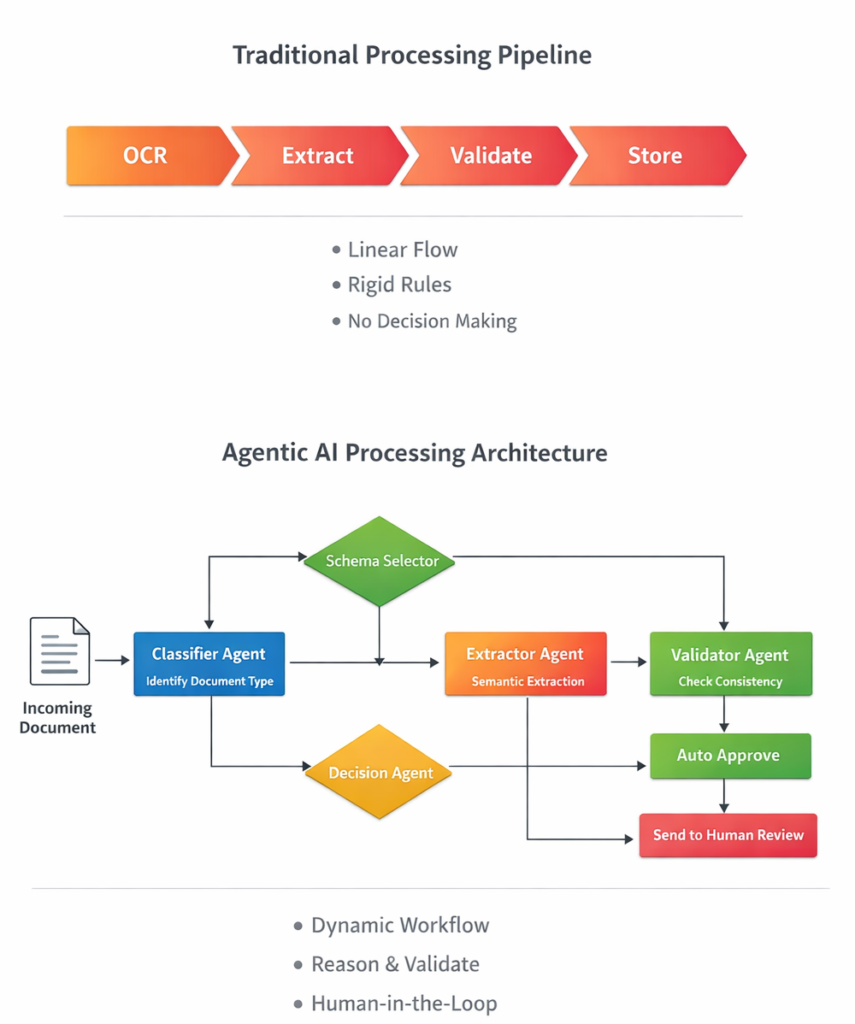
That is not a straight line.
That is a graph.
What LangGraph Adds
LangGraph provides:
- Explicit state management
- Node-based execution
- Deterministic routing
- Clear separation of responsibilities
- Controlled retry logic
This moves the system closer to an enterprise orchestration model, rather than a prompt chain.
Instead of writing logic implicitly inside prompts, the logic is encoded in the workflow graph.
That is a major architectural shift.
Externalized Semantic Schema Layer
Instead of hardcoding document logic like:
if doc_type == "invoice":
required_fields = [...]
I externalized document-type knowledge into a vector store (Chroma) using OpenAI embeddings.
Each document archetype is stored as a semantic definition:
- Invoice structure
- Resume structure
- Contract structure
- Payslip structure
- Bank statement structure
When a new document is uploaded:
- The document is classified.
- The system retrieves the closest semantic definition.
- Extraction is guided using that retrieved knowledge.
This design separates:
- Knowledge (schema expectations)
- Orchestration (flow control)
- Execution (LLM reasoning)
That separation is critical in Enterprise AI architecture.
For reference on embeddings and semantic retrieval:
🔗 https://platform.openai.com/docs/guides/embeddings
🔗 https://www.trychroma.com/
Why the Vector Database Matters in This POC
Without a vector database or incase of POC, vector store:
- This system would only perform classification.
- It would not have contextual grounding.
With the vector database:
- Document schemas are embedded
- Semantic similarity enables intelligent classification
- Retrieval augments extraction
- Cross-document reasoning becomes possible
- Scalability is built-in
The architecture becomes:
Document → Embedding → Vector Store
→ Graph-Orchestrated Extraction
→ Retrieval-Augmented Validation
→ Structured Output + Confidence Score
This is a hybrid deterministic–probabilistic system.
- Deterministic → Graph control flow
- Probabilistic → LLM inference
- Semantic → Vector similarity
That combination is what makes the system production-oriented.
Why This Is Not Just Another RAG Demo
Most RAG demos stop at answering questions.
This system introduces:
- Structured extraction
- Modular orchestration
- Validation-aware processing
- Confidence scoring
- Extensible schema definitions
This moves the system closer to production-grade Intelligent Document Processing systems. However enterprise requirement is much more diverse and complex and will require more refined prompts and varied samples for knowledge base.
If you’re interested in deeper discussions around RAG optimization, see:
Why Retrieval-Augmented Generation (RAG) is so important: Core Concepts Explained – Generative AI & Agentic Systems
Comparing Architectural Alternatives
To understand why this design was chosen, let’s compare alternatives.
| Approach | Pros | Cons |
|---|---|---|
| Rule-Based OCR + Regex | Deterministic | Extremely brittle |
| Monolithic LLM Prompt | Easy to prototype | No control, hard to debug |
| Simple RAG | Good contextual grounding | No multi-step orchestration |
| Graph-Orchestrated Agentic RAG (This POC) | Controlled flow, extensible, modular | Slightly more complex |
The chosen approach balances:
- Flexibility of Generative AI
- Structural discipline of traditional systems
Confidence Scoring: A Step Toward Reliable AI Systems
One major gap in many LLM applications is reliability awareness.
This POC introduces a confidence layer based on:
- Field completeness
- Structural alignment
- Extraction consistency
Although currently heuristic, this design enables:
- Human-in-the-loop routing
- Risk-based automation
- Scalable governance patterns
In future iterations, this could integrate:
- Model log probabilities
- Cross-model validation
- Deterministic rule checks
This aligns with emerging best practices in Enterprise Generative AI systems.
Real-World Applications Across Industries
This architectural pattern applies naturally to:
Insurance Claims Automation
- Multi-document validation
- Policy compliance checks
- Fraud signal identification
FinTech & Underwriting
- Payslip extraction
- Bank statement analysis
- Income verification
Investment Banking (KYC / AML)
- Document classification
- Entity extraction
- Structural compliance checks
- Statement processing
Education Technology
- Transcript parsing
- Certificate validation
- Academic record normalization
For a deeper dive into AI use cases in financial systems:
🔗 https://www.mckinsey.com/capabilities/quantumblack/our-insights
🔗 https://www.weforum.org/topics/artificial-intelligence/
Current Limitations of the POC
This system is intentionally a Proof-of-Concept.
It does not yet include:
- Strict JSON schema enforcement
- Distributed scaling
- Observability & tracing integration
- Multi-tenant architecture
- Security hardening
The document definitions are currently natural language based — not structured JSON schemas.
Which brings us to the next evolution.
Moving Toward Schema-Guided Architecture
The natural upgrade path is converting semantic definitions into structured schema registries:
{
"doc_type": "Invoice",
"required_fields": [
"invoice_number",
"invoice_date",
"vendor_name",
"total_amount"
]
}
This enables:
- Deterministic field validation
- Numeric consistency checks
- Strict schema adherence
- Programmatic confidence scoring
The future architecture becomes a hybrid system:
- Semantic retrieval for classification
- Structured schema enforcement
- LLM for flexible reasoning
This hybrid deterministic–probabilistic model is likely the future of Enterprise AI systems.
Core Architectural Principles Behind This System
- Separate knowledge from execution
- Use orchestration over monolithic prompting
- Introduce validation layers early
- Design for extensibility
- Accept probabilistic reasoning — but control it
These principles align closely with emerging best practices in:
- Agentic AI systems
- Retrieval-Augmented Generation
- LLM orchestration frameworks
- Intelligent Document Processing platforms
Conclusion: From Demo to Deployable AI Systems
Building with LLMs is easy.
Designing reliable, extensible, enterprise-ready AI systems is not.
This POC explores how:
- Agentic AI
- Vector databases
- Semantic schema layers
- Graph orchestration
- Confidence scoring
Can work together to bridge the gap between flexibility and control.
It is not a finished enterprise intelligent document processing product.
It is an architectural exploration.
And in the rapidly evolving world of Generative AI and Intelligent Automation, architecture matters more than ever.
Explore the Code
🔗 GitHub Repository:
https://github.com/sourav-learning/doc-processing-agentic-ai-poc





